Inference Using SSD Weights
Hello and welcome! This week, I took a deeper dive into last week's model, did some additional training, and let me just say, the inference code made predictions, and they’re genuinely impressive!
I kicked off the week by listening to a few podcasts created with Notebook LM, which helped set the stage for deeper understanding. I also spent some time revising the code alongside Claude, going through the model architecture and key components more thoroughly. That combination really clicked for me and I came away feeling like I finally had a much clearer grasp of how the model works.
Once I felt confident in how the model worked, around Wednesday, I decided it was time to train it. Unfortunately, the initial results were pretty disappointing. Every time I kicked off training, the first few epochs showed a really high loss, which wasn’t too surprising at first. But what really threw me off was that the mAP@0.50 stayed stuck at 0.0000 for the first 10 epochs. Even after that, the improvements were barely creeping up with tiny values that were barely meaningful.
After that, I started tweaking some of the weights, hoping to find a sweet spot that would finally unlock the model’s potential. But no matter what I tried, nothing seemed to make a meaningful difference. It was especially frustrating because, on paper, this model had a pretty advanced architecture. It used an EfficientNet‑B1 backbone with an FPN, incorporated sophisticated augmentations through Albumentations, supported mixed‑precision training, and featured a three‑phase learning-rate scheduler. On top of that, the loss function was optimized with GIoU for bounding boxes and Focal Loss for classification, so expectations were high.
But despite all that, after full training, the model only managed to hit around 40 mAP@0.50, which is disappointingly low for a setup this advanced.
By this point, I was honestly exhausted. It was Friday, and I’d spent the better part of the week going back and forth, tweaking weights and adjusting parameters, hoping for a breakthrough. But the model just kept underperforming, no matter what I threw at it. So, naturally, I started thinking about giving up.
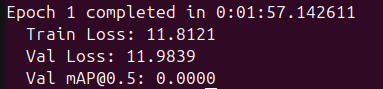
But, I had one last shot left in me.
So, I turned to Claude for some insight. Naturally, I was curious how could a model with such an advanced architecture perform so poorly? I started digging into the original SSD paper, specifically looking at how their model managed to reach 72 mAP@0.5. That’s when it hit me: I had likely overcomplicated my implementation. By layering on too many advanced techniques all at once, I may have introduced more confusion than clarity to the model. Instead of boosting performance, all those additions seemed to interfere with learning.
I decided to simplify the model, keeping the SSD paper as my main reference. Following its approach step by step, I started stripping away some of the complexity and sticking to the core elements of their design. In the end, the model I ended up with was quite similar to the SSD300 from the paper.
So, I started training the simplified model. I think the following snippets really say it all.
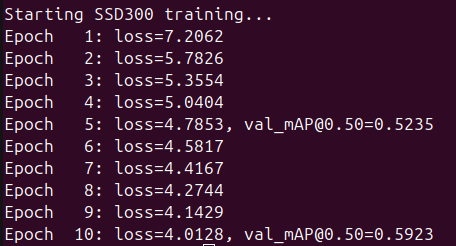
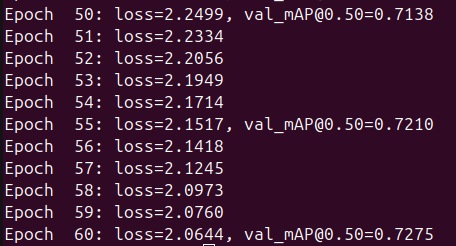
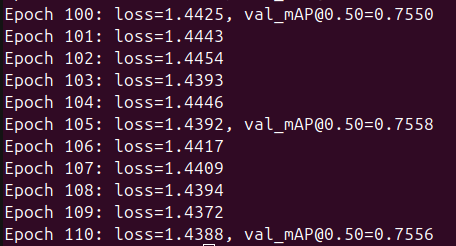
The model finished with an mAP@0.5 of 0.76 (76%), which is very close to the 77% reported in the paper. This marked a huge improvement compared to the 40% mAP of the previous model. But now came the moment of truth: I had to test it out. So, I asked Claude to create two simple sets of inference code, one that randomly selects an image from the Pascal VOC dataset and predicts the bounding boxes and labels, and another where you provide the image manually.
The model did not disappoint.





You can also check out the final trained model weights, now available on Hugging Face. For more examples and the full inference code, head over to the GitHub repo. Feel free to test it, fork it, or build on it!
Next week, I plan to further deepen my understanding by reviewing the newer SSD models and beginning work on the next model for the ML-Rover project. Once that’s complete, I’ll start integrating the models into the Adeept PiCar-B.
This post documents the state of the SSD model as of April 20, 2025
To see the current state of the model visit: