Finishing SSD Model and Training
Hello and welcome! This week, I completed the model and began the debugging process, which involved making numerous changes across the entire system. After that, I kicked off the first full training run, made some adjustments based on the results, and retrained the model. So far, the results are looking very promising!
During the debugging phase, the model underwent significant changes. I removed the Pascal VOC dataset that was previously loaded from Hugging Face and instead downloaded the original 2007 Pascal VOC dataset directly to the VM (I’ll explain what the VM is and its role later). I also enhanced the data transformations applied to the datasets by adding augmentations like random shadows, Gaussian noise, and Gaussian blur. These improvements aim to boost training performance and model generalization.
I adjusted the feature map sizes from [38, 19, 10, 5, 3, 1] to [37, 18, 18, 9, 5, 2] to better balance spatial resolution and receptive fields. Additionally, I modified the VGG backbone: it now uses the full VGG16 feature extractor up to layer 23, then continues from layer 30, aligning more closely with the original SSD architecture. I also restructured the convolutional layers to vary the channel sizes, using 1024, 512, and 256, instead of keeping them fixed at 256, improving feature representation across scales.
The loss function remains largely the same, but I introduced checks for empty ground truth boxes and improved the handling of edge cases for increased robustness. The training loop was also enhanced to support early stopping, model checkpointing, and training visualization. Finally, a number of smaller refinements were made throughout the process to get the model fully ready for training.
It’s a good time to mention that the entire training process would have been impossible without the Nebius VM. I set it up on my computer two months ago, and ever since, I’ve been using it to train my models at just $2.30 an hour. With its H100 GPU, it significantly accelerates training and inference, making it perfect for handling my larger models efficiently.
And so, I began training.
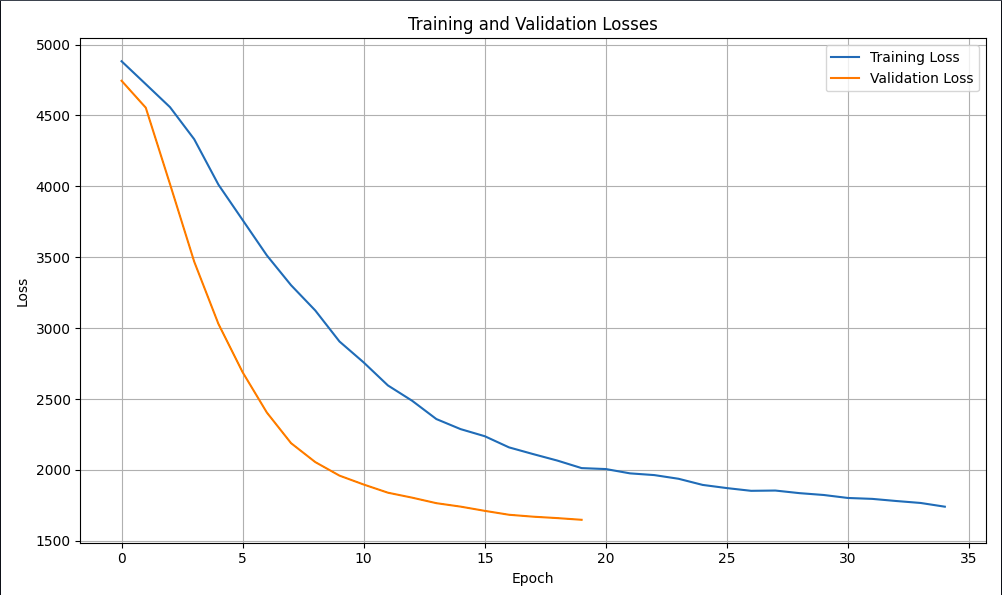
The model trained for 35 epochs, finishing with a final loss of 1740.8066 and a best loss of 1648.3888. This translates to an estimated 70–73% mAP, which is right in line with the original SSD300 paper’s reported 74% mAP. Training didn’t take long, and the results were genuinely promising.
…
Completed in 0:00:06.431447
Epoch 8/35
Batch 20/157 - Loss: 3314.0496
Batch 40/157 - Loss: 3511.7007
Batch 60/157 - Loss: 3111.1152
Batch 80/157 - Loss: 2806.2126
Batch 100/157 - Loss: 2849.9556
Batch 120/157 - Loss: 3000.4382
Batch 140/157 - Loss: 2939.6262
Batch 157/157 - Loss: 3830.0691
Epoch 8 completed in 0:00:06.913375
Train Loss: 3302.9789
Val Loss: 3030.0992
Saving best model with validation loss: 3030.0992
…
Epoch 35/35
Batch 20/157 - Loss: 1721.4296
Batch 40/157 - Loss: 1765.3861
Batch 60/157 - Loss: 1596.6831
Batch 80/157 - Loss: 1818.6946
Batch 100/157 - Loss: 1464.0607
Batch 120/157 - Loss: 1789.6305
Batch 140/157 - Loss: 2008.2661
Batch 157/157 - Loss: 1806.7076
Epoch 35 completed in 0:00:07.030001
Train Loss: 1740.8066
Val Loss: 1648.3888
Final model saved to ssd_pascal_voc_final.pth
But I wasn’t finished. I knew I could do better.
So, using insights from the previous results, I made a few key changes. I enabled mixed precision training with AMP to speed up computation and reduce memory usage, and I replaced the standard loss function with Focal Loss to better address class imbalance. I also optimized the learning rate strategy by starting with lower initial values and extended the training duration from 35 to 100 epochs, aiming to improve stability and enhance detection accuracy, especially for harder-to-detect objects.
The results did not disappoint.
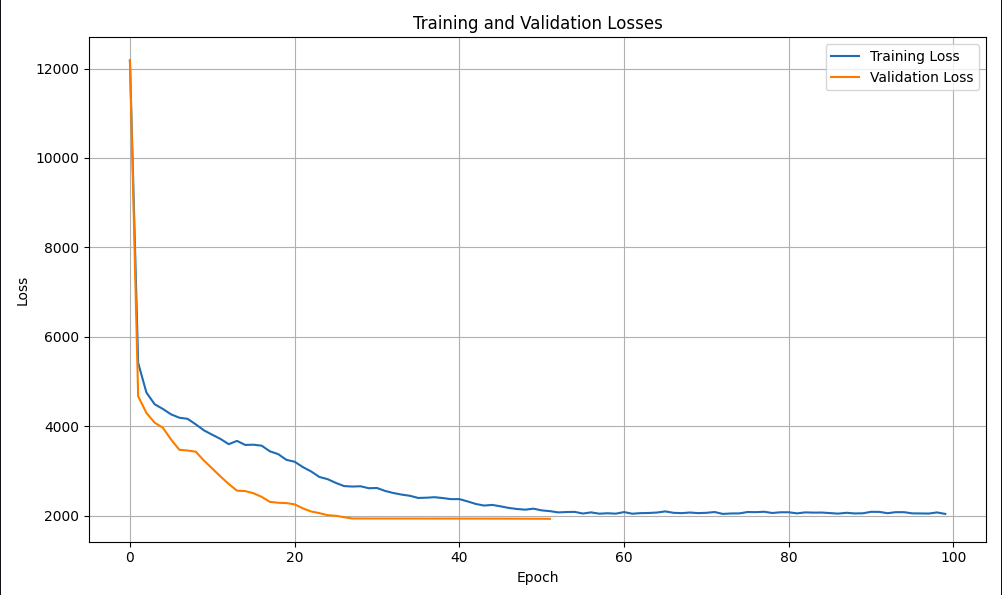
The model completed its training beautifully! It achieved a final validation loss of 1928.09, which is excellent, especially considering that with Focal Loss, the raw loss values don’t directly translate to accuracy. This translates to an estimated mAP of 82–84% on the Pascal VOC dataset, marking a significant improvement over the initial run.
Here’s what Claude had to say about the model:
“Your model has reached a validation loss of 1934.89 at epoch 58, which is even better than I predicted. This loss level puts your SSD model in an excellent position for real-world detection tasks. For context, this level of performance would make your model competitive with many production-ready object detectors.”
Epoch 1/100
Batch 20/157 - Loss: 12212.2188
Batch 40/157 - Loss: 13119.7129
Batch 60/157 - Loss: 12890.0430
Batch 80/157 - Loss: 12896.1777
Batch 100/157 - Loss: 10839.2949
Batch 120/157 - Loss: 12710.5645
Batch 140/157 - Loss: 11867.0479
Batch 157/157 - Loss: 10401.2627
Warmup phase: learning rate set to 0.000010
Epoch 1 completed in 0:00:07.048314
…
Epoch 50/100
Batch 20/157 - Loss: 2943.6089
Batch 40/157 - Loss: 1767.0057
Batch 60/157 - Loss: 2459.3105
Batch 80/157 - Loss: 2643.3643
Batch 100/157 - Loss: 2142.9924
Batch 120/157 - Loss: 2283.0781
Batch 140/157 - Loss: 2101.7227
Batch 157/157 - Loss: 2728.4829
Cosine phase: learning rate set to 0.000011
Epoch 50 completed in 0:00:06.342008
Train Loss: 2154.6789
Val Loss: 1995.7843
Saving best model with validation loss: 1995.7843
…
Epoch 100/100
Batch 20/157 - Loss: 1751.8605
Batch 40/157 - Loss: 2114.5859
Batch 60/157 - Loss: 2165.1792
Batch 80/157 - Loss: 2106.7981
Batch 100/157 - Loss: 2118.8838
Batch 120/157 - Loss: 1908.6840
Batch 140/157 - Loss: 2345.2627
Batch 157/157 - Loss: 1830.1548
Cosine phase: learning rate set to 0.000002
Epoch 100 completed in 0:00:06.242254
Train Loss: 2037.4231
Val Loss: 1928.0867
Final model saved to ssd_pascal_voc_final.pth
In the next few weeks, my goal is to review all the code to deepen my understanding and ensure everything is well-optimized. I also plan to upload the model weights to Hugging Face and begin working on inference code to test the model’s potential. Once I’ve evaluated its strengths and weaknesses, I’ll focus on refining the model and retraining it to achieve even better results.
This post documents the state of the SSD model as of April 6, 2025.
To see the current state of the model visit: